1850 words, 7 minutes.
…or, how the cave fish lost his eyes.

Iranocypris typhlops - 1944, By B.Coad for Bruun & Kaiser.
This post follows directly from the last. In that post, we learned that everyone could do something to reduce their attack surface and decrease the likelihood of a breach. I’m going to show you what that winning system looks like when taken to its ultimate logical conclusion. The logic goes something like this:
- Software security flaws are commonplace.
- An increase in size and complexity of software is unavoidable.
- These facts will not change in the foreseeable future.
The chances of dramatically reducing the incidence of exploitable vulnerabilities look bleak. We are reduced to:
- Better software design.
- More comprehensive testing/checking during the development process.
- Stopping bad things in real-time with additional products and technologies.
Excellent work has been done in all three areas. However, each provides only a marginal improvement.
- Better software design assumes an increase in skill and rigour, hard to attain, harder still to maintain.
- Improved testing scales better but is still a challenge. It requires that any tools understand and identify flaws in code with a sufficiently low false positive rate that developers enthusiastically embrace them.
- Stopping bad things happening in real-time is where most of the Information Security product market sits. Detecting, blocking, sanitising, alerting, containing. A never-ending struggle and ever-increasing cost.
If software is vulnerable and always will be, can we have less of it? Can we have not just less, but the least? The fewest lines, the tiniest number of OpCodes, the smallest list of instructions. Not just the fewest running, but the fewest runnable. Under any circumstance. Regardless of whether the software is behaving normally or has been somehow subverted.
What does minimum software look like and how do we get to it?
That is the question this post explores.
Consider web servers like this one. The first CERN httpd provided little functionality and had a small codebase. Today web servers are a microcosm of the entire information technology universe. Authentication, administration, database integration, performance management, interpreters. You name it, someone has added it to a web server. They are large and complex applications in their own right. Apache httpd has over 390K lines of source code.
| Software | MLOC | CVEs To Date |
|---|---|---|
| CERN-httpd1 | 0.045 | 0 |
| NGINX | 0.167 | 25 |
| Apache-httpd | 0.391 | 288 |
Pareto’s Wager
Have you ever heard someone say “I only use 20% of [$SOFTWARE]”? It’s often true for productivity tools like Word, or Excel. There is a degree to which it’s true for server software too. Including our example, web servers.
What about the other 80% of the features? What about the other 80% of the code? What about the vulnerabilities in that 80% of the code? Assuming an even distribution of vulnerabilities to features, and features to code, 20% of the value in that software lands you with 100% of the attack surface. That means potentially 100% of the exploitable vulnerability. That doesn’t sound like a good deal.
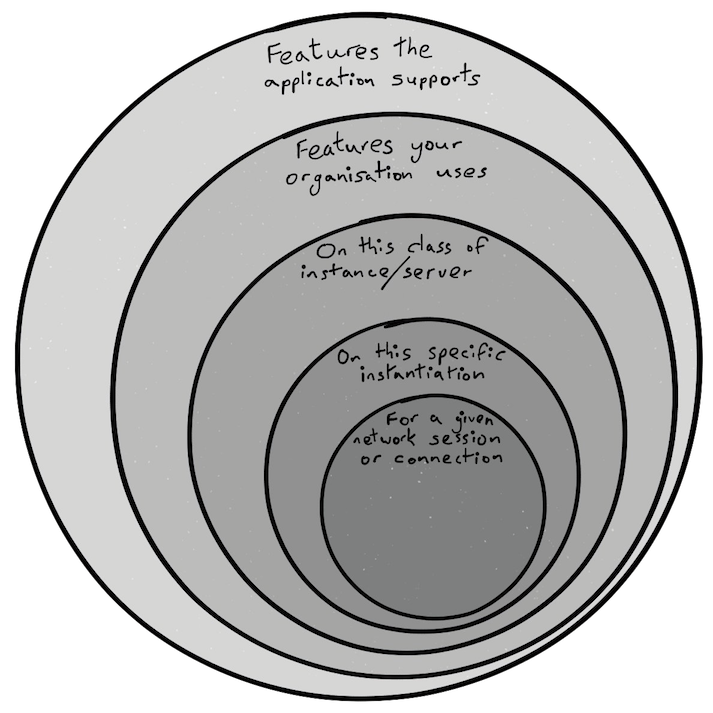
Imagine vulnerabilities are sprayed randomly across this diagram. Some more serious than others. What if we were only exposed to those vulnerabilities within the smallest circle? How might that transform our security outcome? Such a uniform distribution of vulnerability is simplistic, but it would be surprising if there were only a weak correlation of circle size to vulnerabilities contained therein.
The circle size is arbitrary. It’s a sketch. This is a blog, not a PhD thesis. Consider this though:
Because of how software is built today, there may be code included that will never and can never be executed by a legitimate user. Code which doesn’t even provide a working feature. Not all such code can be optimised away by the compiler. It’s part of the dubious inheritance you get with cut/paste software construction. The 80-20 may become 85-15 or 90-10 when the binary meets the road.
To take this winning system to its ultimate logical conclusion, we must re-think the whole matter of the software runtime.
Just Not This Time
Modern compilers may optimise for binary size on disk, runtime memory footprint, performance, and ease of debugging. They accept a myriad of other directives shaping the way source code is turned into object code and linked in a binary you can run. Unfortunately, they can’t know which subset of functions or features within an application a particular user will need. They can’t predict the future. The one kind of compiler which gets closest to the future is the “Just In Time” (JIT) compiler.
JIT is not a security mechanism. It’s something to give an interpreted language some of the speed of a compiled one. It places no restrictions on what’s compiled nor executed from a security standpoint. JIT understands how frequently a function is called at runtime. It evaluates whether to invest cycles in partially or fully compiling code during repeated runs. That’s all. It doesn’t know whether you should be running a particular routine or function. JIT doesn’t know whether executing some part of the code is expected behaviour. It doesn’t get us to minimum software. JIT isn’t it.
We’ll stick with web servers as an example. Modern web servers aid the limitation of attack surface through the use of optional modules. The administrator decides at install or configuration time which of dozens of modules to enable. Each provides some non-core functions. The conscientious administrator begins with no modules and adds those he needs. As his site requires he may add or retire further modules over time.
The less conscientious administrator starts with the defaults, which may include lots of modules he doesn’t need nor will ever need. He adds extra modules over the lifetime of the server as his site demands. He probably never has an audit nor removes unnecessary modules. Something might break for want of one of them. As a consequence, the attack surface grows and grows.
Why did the modular approach to web servers come about? Perhaps it was to reduce complexity and memory footprint in the core application. Perhaps it made contributions to the project easier to integrate and manage. I doubt it was for security reasons. I’ll take the security dividend though, even if it was unintended. The result is far better than a monolithic approach.
It’s still not minimum software.
- Weak module “housekeeping” by administrators isn’t changing.
- We must still contend with vulnerabilities in the core.
- Granularity is at the module level, not the function/feature level.
- Default included modules could still be surplus to our needs, and vulnerable.
Hyper-modularisation, designing the core of an application more like a microkernel would help to address (2). However, one could argue that it does little for (3) and places increased emphasis on (1). (1) is where we are most reliant on human conscientiousness. Relying on human conscientiousness is not a winning system. Getting to minimum software is tough.
Minimum Viable Functionality
We’ll continue with the web server example. By now I’d like you to be thinking about any large application you might expose to a hostile environment.
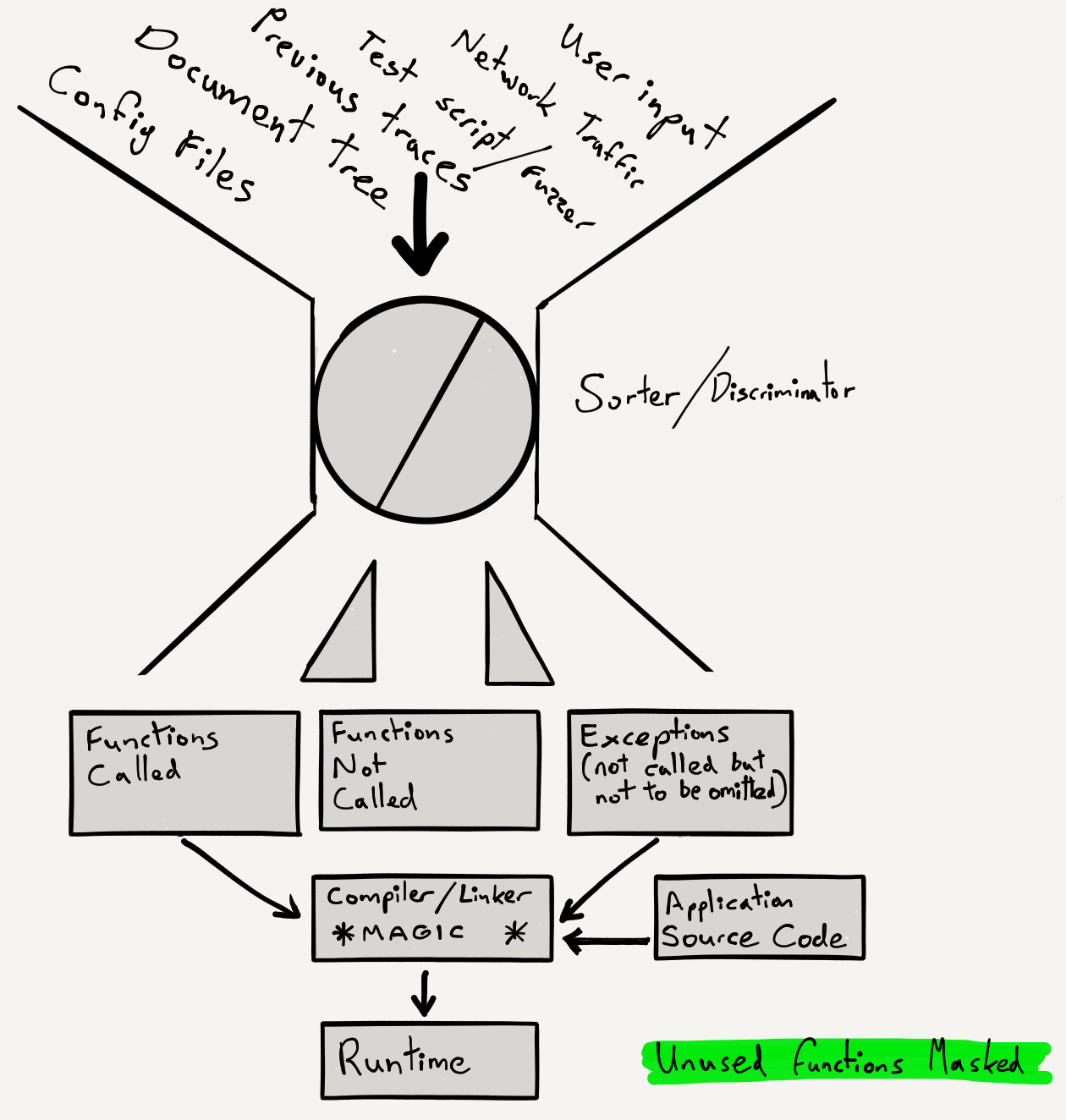
- What if we could parse config files and know what features were being used?
- What if we could similarly evaluate the web site document tree?
- What if we could profile the application using session replays?
- What if we could record the functions called during test runs?
- What if this provided us with a minimal list of functions for our specific use?
- What if we tagged functions in source/object/executable as used or not used?
- What if we masked, “stubbed”, or shed functions that we never used?
- How close does that get us to the smallest circle in my first diagram above?
- What would that do to our exploitable attack surface?
Performance
Performance is always a concern. Could such masking of unused code be achieved in a way which doesn’t harm performance?
- It doesn’t require a rewrite of the application nor change fundamental performance characteristics.
- But “costly” per site, instance, and use case recompilation is needed.
- However, that cost is up-front (compile-time or shortly thereafter).
- The parts of the application you actually need are unchanged.
- Functions and routines that are never needed are “stubbed”.
- Functions which might be needed can be designated immutable.
This is a 2-stage process. Stage 1 consists of profiling with inputs drawn from the dynamic, site-specific sources described above and shown in the diagram. The second stage is to “stub” or mask unused code. As for the exact method by which the application is prepared and unused functions neutralised, one might evaluate several options. These may include automated source code patching at the pre-processor stage or manipulation at the linker stage. A less desirable option might be the direct modification of the binary, post-linking.
Our example of a web server is challenging because web development and servers are fast-moving areas of technology. Not only the configuration files but also the document tree impacts what code remains unvisited and therefore can be excluded.
Related Research
I’m not aware of this exact approach being described previously. However, a related paper2 was published just as I was finishing this. It proposes a method for the elimination of “software bloat”. The authors characterise bloat as the inclusion of unnecessary code gadgets within an application. They examine the efficacy of automated removal of gadgets as a means of reducing the likelihood of successful code reuse attacks. Their results suggest a human in the loop is desirable and superior to purely automated methods.
My proposal is a more radical one. I propose the elimination of any part of the application you are not using, on a per site or per instance basis based upon the inputs listed. I also propose a form of “human in the loop” or override mechanism, shown in the diagram as “exceptions”. I do so for a different reason. It’s to prevent the “stubbing” of routines known to to be essential, without which the application would cease to function for that particular use case or instance.
Conclusions
If you never use it, you don’t need it, so don’t keep it. Then it can’t hurt you. You won’t miss it.
The cave fish wasn’t always blind. When rains first created his cave and flooded its floor, he had eyes just like his cousins in the river. Above ground, eyes were an advantage. In the darkness they weren’t only useless, they were a liability. Costly from an evolutionary and biological perspective. Easy to damage. A waste of precious brain cells too. Not just an encumbrance, his eyes were a source of vulnerability. Their usefulness was specific to the environment. Over time the cave fish’s eyes disappeared. His descendants faired all the better for losing them.
Lines of code you’ll never use in your environment have no value. Worse than that, they’re just a source of vulnerability. Isn’t it time you evolved?
-
The figures are for the most recent version of the original CERN httpd codebase. CERN httpd is considered complete. The final release was 1996. It is likely that it has security vulnerabilities, although the code base is tiny. ↩︎
-
Brown & Pande. “Is Less Really More? Why Reducing Code Reuse Gadget Counts via Software Debloating Doesn’t Necessarily Lead to Better Security”. arXiv:1902.10880 [cs.CR] Georgia Institute of Technology, 2019. ↩︎